
ComfyUI 基本T2I工作流
ComfyUI 是一个基于 节点工作流(Node Graph) 的 Stable Diffusion 推理界面。
特点
- 所有的流程都可视化
- 每一步可控(加载模型 / 编码 / 采样 / 解码)
- 适合复杂工作流:二创、视频、风格叠加、多 LoRA
简单来讲不光是输入prompt按下按钮就生成内容,而是搭建一条内容生产工作流。
最基础文生图T2I工作流如下:
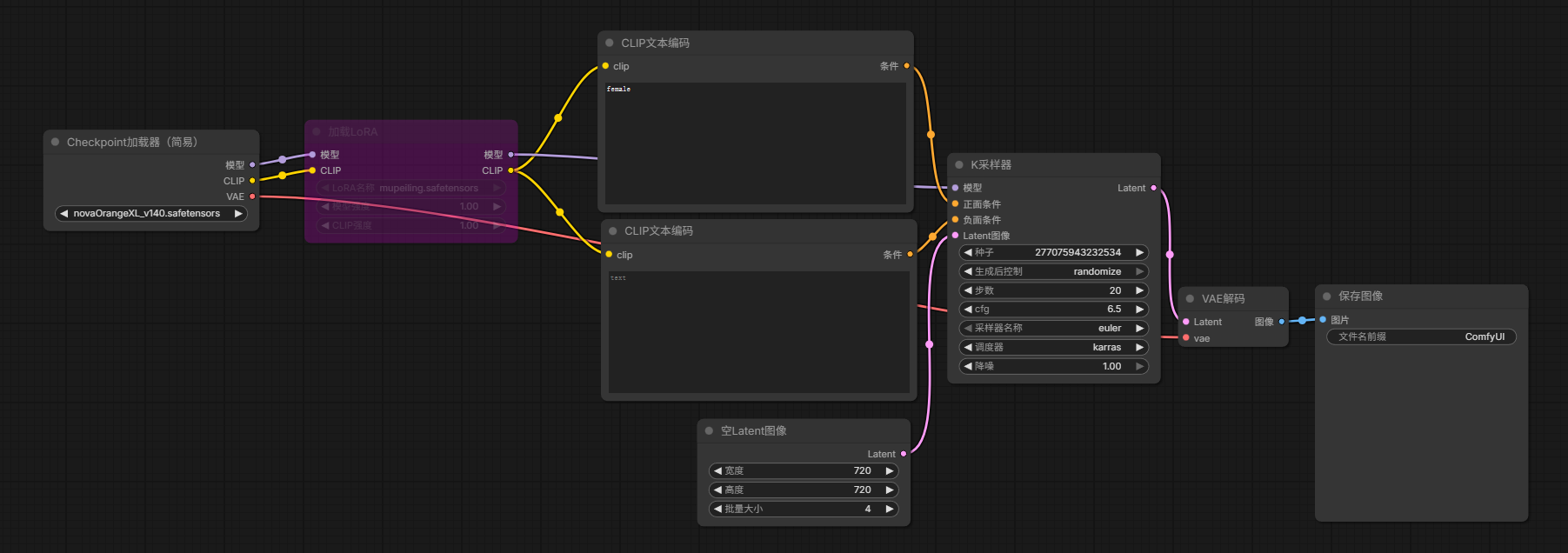
模型文件
属于是整个工作流的大脑,模型文件一般存放在 ComfyUI/models/checkpoints/ 目录,常见的后缀有 .ckpt 和 .safetensors(更安全,推荐)。
Checkpoint
用于加载大模型(底模),会提供 CLIP 权重和 VAE 权重,可以分别接入到 CLIP 文本编码 和 VAE 解码。
CLIP 文本编码
因为模型不认识文字,只认识数字向量,所以它的唯一使命就是负责把传入的提示词转换成向量,参与模型计算。所以任何采样器前都必须有 Text Encode 。
存放在 ComfyUI/models/clip 目录下。
VAE
作用是在"模型能算的潜空间和最终能看到的内容"之间做翻译 。这里指的"潜空间"就是模型的高维向量世界,但我看大家都称为"潜空间",模型所有的处理都是在这里面完成的。
比如一张图片要进入到模型内做运算,也需要通过 VAE 编码才能进入潜空间。反之,人要看到潜空间里的最终运算结果,也要通过 VAE 解码才能看到最终的内容。所以 VAE 在工作流里一定是最前和最后的。
存放在 ComfyUI/models/vae 目录下,有些 checkpoint 自带 VAE,但也可以外接更清晰的。
LoRA
这个属于"模型的微调补丁",是基于某个模型训练出来,不是完整的模型。所以它需要叠加在模型上才可以使用,这里被叠加的模型就叫"底模",并不是说必须指定某个底模才可以使用,但必须是同一个模型体系(比如 SD.1.5 / SDXL / FLUX)
一般流程就是: Checkpoint / Unet -> LoRA Loader -> K采样器
经典用途就是训练出某个特定的人脸、画风、服装、表情等,本质上就是模型的补丁。
K 采样器(KSampler)
最关键的节点之一,有很多参数直接关系到最终内容。
常见参数:
Seed 随机种子
通常会有一个随机数,让模型最终输出的内容变得不一样,一般来讲都会让他随机生成。如果种子一样,其他参数一样,那最终的结果也会几乎一样。
- 固定 seed: 用于微调参数对比效果
- 随机 seed: 抽卡,生产时使用
Steps 步数
就像人画一张图所需要的步数,这里大模型绘制时也需要。理论上越高细节就越多,但超过了一定值反而会起到画蛇添足的作用,就比如我画一张图只要20笔你却要我画100笔我只能乱涂了。
- 越高:细节越多,但对性能消耗也越高
- 收益递减
一般推荐图像是 20 - 50,视频 10 - 20,主要取决于大模型的能力。
CFG 提示词强度
控制模型的"听话程度",一般模型越强这个值越低,我的粗略理解
- 低:更自由,可能跑偏
- 高:更贴近提示词,但可能比较僵硬
Denoise 降噪
这是个非常重要的参数,拿一个具体场景来说,比如在图生图I2I的过程中,我要对原来的图片进行调整(将背景改为故宫之类),在过程中就会在原来图片的基础上加上噪点。
通常文生图是1,因为是 0 到 1 的过程,在图生图中就需要调整这个值了 0.3 - 0.7 之间。太低的话原图几乎不变(没有噪点就不会做更改),太高的话直接变成新图(全是噪点就和原图没关系了)。可以理解为模型对内容的改变程度。
Sampler_name 采样器
数值积分方式,这个配置关系到取什么样的采样算法。
没有看到太多解释,看下来大家的经验建议就是:
- 写实:dpmpp2m
- 真人:dpmpp2m_sde
- 动漫:euler
Scheduler 调度器
可以理解为每一步噪点减少多少的时间分布。
这里我也无脑选大家建议的 karras。(前期更细,后期更快更稳)
Latent 画布
K采样器需要的参数,这个可以理解为潜空间里的画布,在进行一顿操作之后通过 VAE 解码输出到我们的眼前。
- 文生图的时候可以接一个空 Latent
- 其他需要传入图片的时候就需要用 VAE 编码到 Latent 再接进去
Workflow 工作流
ComfyUI 还有一个好处就是工作流可以直接导入,所以很多大佬会在各平台上传自己工作流。常见的比如图片转高清,图片放大,还有一些以前需要在 PS 才能完成的操作等。
页面推荐
C 站,可以下到很多资源: https://civitai.com/
提示词推荐:https://promlib.com/
评论 (0)
请登录后发表评论